Imagine a very common situation — you need to write a string-processing
function. Say, the input string contains a = character, and you have to grab
everything to the left of it, drop all non-letter characters, and change the
case of all letters inside. Like I said, totally common and makes plenty of
sense.
Anyway, you might start with a function that will generate a test string for you (you aren't gonna type the damn thing manually, are you?)
(require '[clojure.string :as str]
'[criterium.core :as crit])
(defn rand-string [length]
(str/join (repeatedly length #(let [i (+ 33 (rand-int 94))]
(char (if (= i 61) ;; Exclude =
62
i))))))
(def test-string (str (rand-string 50) \= (rand-string 50)))
Great, now, armed with the top of the line functional programming techniques, you write the first solution to the task at hand.
(defn solution-1 [s]
(let [before-= (second (re-matches #"([^=]+)=.+" s))]
(->> before-=
(filter #(Character/isAlphabetic (int %)))
(map #(if (Character/isUpperCase (int %))
(str/lower-case %)
(str/upper-case %)))
str/join)))
First, we use a regular expression to find a substring to the left of the equality symbol. Then we filter out non-alphabetic characters and switch the case of the remaining ones. Finally, we join the characters back into a string. Now, it's time to benchmark your creation. Our old friend Criterium will help.
user=> (crit/quick-bench (solution-1 test-string))
Evaluation count : 41664 in 6 samples of 6944 calls.
Execution time mean : 11.480507 µs
Execution time std-deviation : 2.362996 µs
Execution time lower quantile : 9.627715 µs ( 2.5%)
Execution time upper quantile : 14.706372 µs (97.5%)
Overhead used : 1.856322 ns
Not too bad, but still a tad slow. Eleven microseconds per call — it's OK if you have to call it once or twice. However, if this function is going to be used millions of times per second, you'll probably need something faster.
A colleague looks at your struggle and tells you that converting a string into a lazy sequence is not very efficient. "What you need", they say, "is raw character arrays. And while you are there, replace the function wrappers with Java interop."
So, this time you leave all the FP nonsense behind and drop to the stuff that the real folks use.
(defn solution-2 [s]
(let [before-= (.substring s 0 (.indexOf s "="))
arr (.toCharArray before-=)
lng (alength arr)
new-arr (char-array lng)
new-lng (loop [i 0, j 0]
(if (>= i lng)
j
(let [c (int (aget arr i))]
(if (Character/isAlphabetic c)
(do (aset new-arr j (char (if (Character/isUpperCase c)
(Character/toLowerCase c)
(Character/toUpperCase c))))
(recur (inc i) (inc j)))
(recur (inc i) j)))))]
;; Create a result string from the filled part of new-array.
(String. new-arr 0 new-lng)))
This function is clearly much more complicated. First, we find an index of =
in the string and cut the left part using .substring. Then, we construct a
character array with the same length as the original one. We will add the final
characters into this array. Now we go over the original array in a loop,
tracking the current index in the input array (character we are currently
processing) and the index in the resulting array (place where the processed
character will go). Finally, we return the output array length from the loop and
construct a string of that size.
Note, that even though we are working with arrays directly, we still have to do
explicit casts to int and char. It's because aget cannot return a
primitive type since it's the same function for any array type; so, it returns a
boxed Object.
Whew. Look how much more text is needed just to describe this solution. At least, it's going to be faster.
user=> (crit/quick-bench (solution-2 test-string))
Evaluation count : 1254 in 6 samples of 209 calls.
Execution time mean : 473.388358 µs
Execution time std-deviation : 11.003881 µs
Execution time lower quantile : 457.440474 µs ( 2.5%)
Execution time upper quantile : 485.452856 µs (97.5%)
Overhead used : 1.856322 ns
Wait, what? You went through all these lengths to get a 40 times slower solution? Screw this, Clojure sucks! Closes Emacs.
Please, don't rush to conclusions. It is very easy to speed up this code if you can identify the cause of the slowdown. And you now know how to do it using VisualVM. Let's rerun the last benchmark with the sampling profiler on.
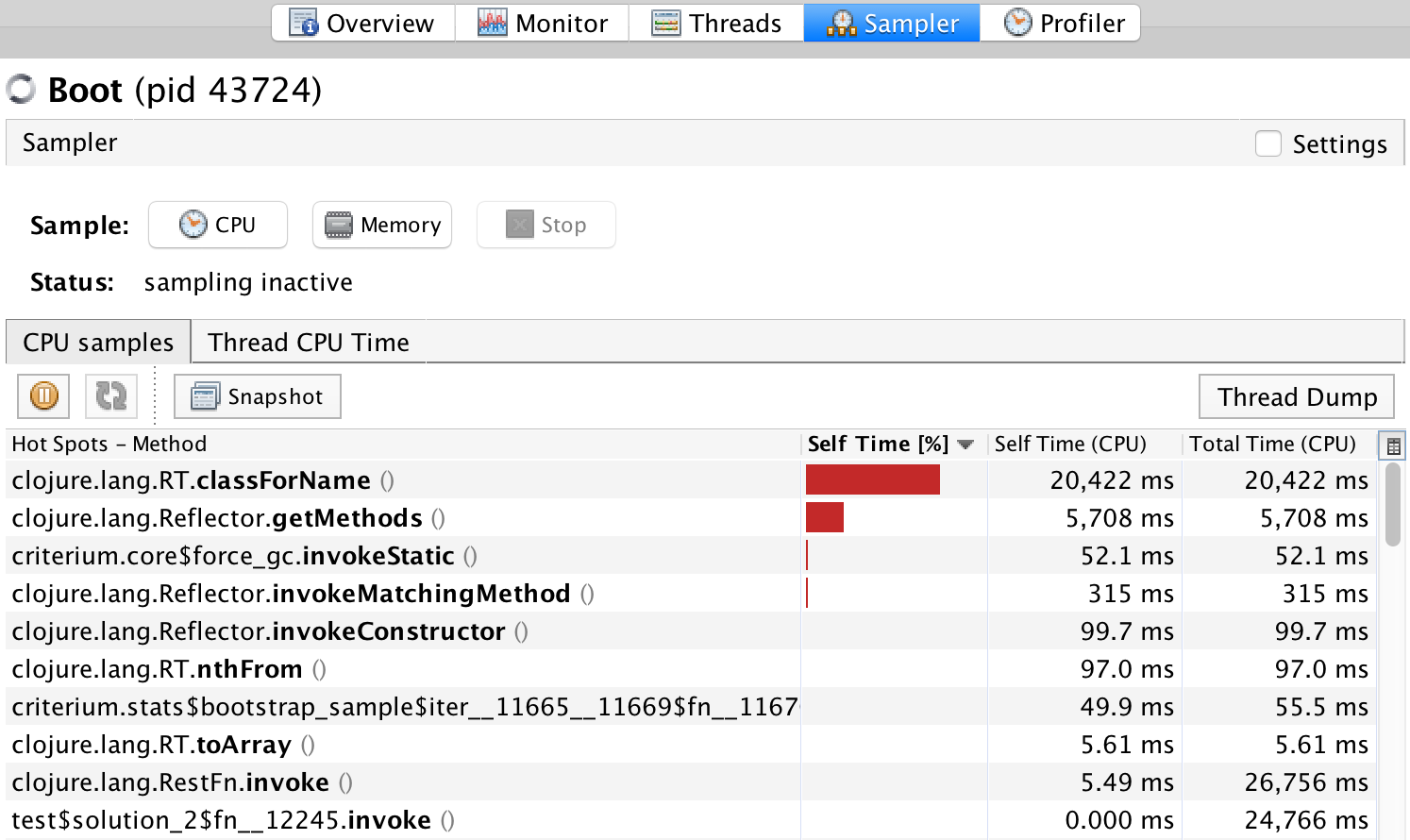
We can see that RT.classForName and Reflector.getMethods completely dominate
the profile. What are those and how to get rid of them? To get the answers we'll
first need to understand what is reflection and why it exists.
You probably already know that JVM (Java Virtual Machine) executes this special assembly-like language called Java bytecode. Everything you write in Java, or Scala, or Clojure, will be first compiled into this bytecode and only then executed. The building blocks of Java bytecode are classes, methods, and instructions. There are many different bytecode instructions, like arithmetic operations, operations on arrays, working with stack; but the most common one is method invocation.
Method invocation, unless the method is static, requires an object and a method (and, optionally, method arguments). Let's say, you write in Java:
String foo = "mycustomstring";
foo.isEmpty();
In the bytecode this will look like:
<put the string foo on stack>
invokevirtual #3 // Method java/lang/String.isEmpty:()Z
Notice how in bytecode the isEmpty method is no longer just a name — it
resolved into a fully qualified name String.isEmpty. The JVM cannot "guess"
which isEmpty we wanted to call, so it needs a direct pointer to the exact
method to be invoked. Now, this isn't a problem in Java since it is statically
typed. The compiler wouldn't let you compile the code above if foo was
declared as an Object, so Java knows at compile-time which class isEmpty
belongs to.
Contrast this with Clojure. This is a perfectly valid Clojure code:
(defn empty? [s] (.isEmpty s))
How can Clojure compiler (the thing that turns Clojure code into Java bytecode)
possibly know which class is .isEmpty from? It can't. Instead, it says: "I'm
going to see what type of object comes here at runtime anyway, so I'm going to
defer the decision until then." And to able to find that direct method handle at
runtime the compiler uses reflection.
Although the word "reflection" in Clojure is often painted as "bad", the
reflection itself is not a bug, it's a feature. JVM's reflection is analogous to
Clojure's find-ns and resolve — it allows at runtime to locate and use
certain things that are usually only available at compile time. The downside of
it, of course, is that it is slow. To find the correct method handle at runtime
the JVM has to get all methods of a class (as an array) and then linearly go
over them comparing to the target method name using, basically, string equality.
You can imagine that this is way slower than jumping directly to a predefined
address in memory, as happens with statically resolved methods.
Keep in mind that in Clojure the reflection only happens on the boundary between Clojure and Java code. Since Clojure is a dynamic language, it has its own efficient utilities for runtime dispatching.
Now, you know what reflection is, and that it causes performance issues for us. Next step is to find out where the compiler had to use reflection. Put the following line at the beginning of the file and recompile everything:
(set! *warn-on-reflection* true)
In the REPL you'll see something like this:
Reflection warning, /path/to/core.clj:27:34 - call to method indexOf can't be resolved (target class is unknown).
Reflection warning, /path/to/core.clj:27:18 - call to method substring can't be resolved (target class is unknown).
Reflection warning, /path/to/core.clj:28:13 - reference to field toCharArray can't be resolved.
Reflection warning, /path/to/core.clj:29:13 - call to static method alength on clojure.lang.RT can't be resolved (argument types: unknown).
Reflection warning, /path/to/core.clj:34:34 - call to static method aget on clojure.lang.RT can't be resolved (argument types: unknown, int).
Reflection warning, /path/to/core.clj:42:5 - call to java.lang.String
ctor can't be resolved.
The compiler pleasantly pointed us to places where it could not resolve the
invoked method. What can you do with this information? In fact, Clojure provides
a way to help the compiler do the static resolution by
placing type hints. The
syntax for a type hint is putting ^Klass (e.g., ^String) in front of an
object.
Clojure syntax allows placing the type hints in local bindings (e.g., in let
or defn arglist), before an expression that returns an object, and before the
function name or arglist in defn (to signify that the function returns objects
of that type). Here are the examples of type hinting:
(let [^String s (something-returning-a-string)]
(.isEmpty s))
(defn empty? [^String s]
(.isEmpty s))
(.isEmpty ^String (something-returning-a-string))
(defn ^String myfn []
"I'm a string")
(defn myfn2
(^String [] "I'm a string")
(^String [a b] "I'm a string too"))
It is time to revise our solution-2 function and place a few strategic type
hints to make it fast. Turns out, you can remove all reflection with just three:
(defn solution-3 [^String s]
(let [before-= (.substring s 0 (.indexOf s "="))
^chars arr (.toCharArray before-=)
lng (alength arr)
new-arr (char-array lng)
new-lng (loop [i 0, j 0]
(if (>= i lng)
j
(let [c (int (aget arr i))]
(if (Character/isAlphabetic c)
(do (aset new-arr j (char (if (Character/isUpperCase c)
(Character/toLowerCase c)
(Character/toUpperCase c))))
(recur (inc i) (inc j)))
(recur (inc i) j)))))]
;; Create a result string from the filled part of new-array.
(String. new-arr 0 ^int new-lng)))
Things we've type hinted:
^String s in function arglist^chars arr^int new-lng at the resulting String constructionWhen you compile solution-3, there will be no reflection warnings. But wait,
we didn't type-hint every local binding! Well, we didn't have to. Clojure
compiler is quite good at figuring out the types of objects where it can track
them. It's not a full-blown type inference like Haskell has, but it's still
something. Thus, the compiler could infer that before-= is a String (because
String.substring always returns a String), and the expression (.toCharArray before-=) was statically resolved even without a type hint.
You might ask: why does the call to alength and aget cause reflection to
happen? Aren't they supposed to know that they work on arrays?
In Java, arrays are a unique beast. They look like objects; you can call methods
on them (like equals and toString). But it's only an illusion created by the
Java compiler. In practice, arrays are not objects, they are treated
individually by the runtime, and what's important, they don't share the same
ancestor. There is no such thing as an abstract array in Java, so length
called on an array of chars and an array of doubles would be two entirely
different lengths. Same goes for array element accessors. Getting an element
from int and double array are two separate bytecode operations, iaload and
daload respectively.
It means that when you work with arrays in Clojure, you have to make sure that
the type of the array is known to the compiler. The type hints for primitive
arrays are ^longs, ^chars, ^doubles, etc.; for arrays of objects you have
to use an unwieldy construct like ^"[Ljava.lang.String;".
Enough chit-chat, you say, let's see the numbers.
user=> (crit/quick-bench (solution-3 test-string))
Evaluation count : 1767324 in 6 samples of 294554 calls.
Execution time mean : 327.875654 ns
Execution time std-deviation : 56.423296 ns
Execution time lower quantile : 285.966821 ns ( 2.5%)
Execution time upper quantile : 400.424857 ns (97.5%)
Overhead used : 1.856322 ns
Amazing, it's just 328 nanoseconds. This is 35 faster than solution-1 and
almost 1500 times faster than solution-2. Way to go, type hints!
*warn-on-reflection* warnings be your guide, and don't sprinkle
excessive type hints "just in case".doc output, and the person who reads the code might be
confused about their intent. Spec is a
much better tool for this.Type hints are one of Clojure's methods that cover some of the performance lost due to dynamic typing. When used sparingly, they can improve the execution speed of your code. Just don't overdo them, and may your Clojure go as fast as possible!